In the Shadows of Dependency: Can AI Unmask the Hidden Threats Lurking in the Software Supply Chain?
ECE 570 Research Project
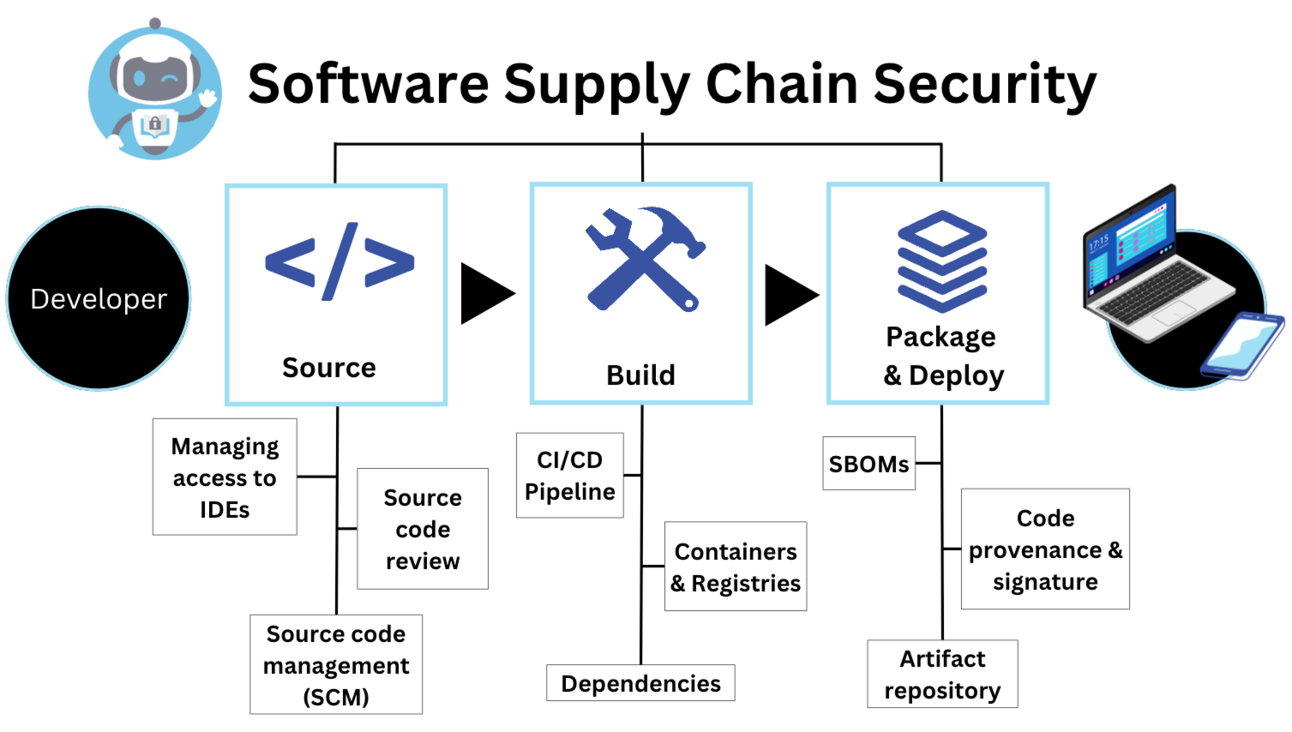
Project Overview
This ECE 570 research project presents a comparative analysis of traditional manual methods and LLM-based approaches in identifying and analyzing software supply chain failures. Building on previous studies by Singla et al. (2023) and Anandayuvaraj et al. (2024), we demonstrate how Large Language Models, particularly with advanced prompt engineering techniques, can enhance the accuracy and efficiency of software failure analysis.
Abstract
In the interconnected landscape of modern software development, the increasing reliance on third-party dependencies has heightened the risk of supply chain vulnerabilities. Manual analysis of such vulnerabilities is often time-consuming and resource-intensive. Recent advancements in the use of Large Language Models (LLMs) have shown promise in automating this process, potentially reducing costs and improving response times.
Key Research Contributions
- Comparative Analysis: Comprehensive evaluation of current methods to solve software supply chain failures
- LLM Enhancement: Evaluation of suggested improvements upon existing methods using advanced prompt engineering
- Performance Improvement: Demonstrated significant accuracy gains using GPT-4o and Gemini 1.5-pro models
- Prompt Engineering: Developed and refined advanced prompting techniques including one-shot and few-shot learning
- Dataset Extension: Extended previous work using CNCF's "Catalog of Supply Chain Compromises" dataset
Technical Achievements
- GPT-4o Performance: Achieved 66% accuracy in Type of Compromise classification (vs 59% with GPT-3.5)
- Impact Analysis: Improved accuracy from 50% to 70% in Impact dimension analysis
- Nature Classification: Enhanced Nature dimension accuracy from 69% to 84%
- Gemini Integration: Demonstrated 65% accuracy in Type of Compromise (vs 35% with Bard)
- Prompt Engineering: Achieved 85% accuracy using one-shot prompting techniques
Methodology
- Dataset: Used CNCF's catalog of 69 software supply chain security failures (1984-2022)
- Models: Evaluated OpenAI's GPT-4o and Google's Gemini 1.5-pro
- Prompt Engineering: Implemented cumulative refinement with context definitions, reflection patterns, JSON formatting, and one-shot examples
- Evaluation Metrics: Accuracy, F1-score, and holistic analysis across multiple dimensions
- Comparative Analysis: Extended previous work by Singla et al. (2023) with improved techniques
Key Findings
- LLMs can effectively replicate manual analysis and with further improvements replace human expertise
- Advanced prompt engineering techniques significantly improve classification accuracy
- GPT-4o shows substantial improvements over GPT-3.5 across all analyzed dimensions
- Gemini 1.5-pro demonstrates near-doubling of accuracy in Type of Compromise classification
- One-shot prompting with structured responses achieves highest accuracy levels
Technologies Used
Research Impact
This study provides a foundation for leveraging LLMs in proactive software supply chain risk management, with potential applications beyond the software industry. The findings indicate that LLMs are not only capable of addressing the time and resource limitations associated with traditional manual approaches but also excel at capturing nuanced dependencies within complex datasets.
Future Directions
- Extension of LLM use beyond software industry to healthcare, finance, and critical infrastructure
- Integration of multimodal models for visual data analysis
- Refinement of LLM interpretability for better decision transparency
- Continued advancements in fine-tuning and prompt engineering techniques
Project Details
Course: ECE 570 - Advanced Topics in Computer Engineering
Institution: Purdue University
Code Repository: https://anonymous.4open.science/r/ECE-570project-4C6B
Submission Type: Anonymous submission
Research Focus: AI-driven software supply chain security analysis